THIS PAGE IS UNDER CONSTRUCTION
Course Structure
Day 1
AM Session - 2-3 hours followed by a troubleshooting session
- Basic Unix
- Introduction to HAWK
- Basic Unix continued
- Fetching data with nf-core/fetchngs pipeline
Day 2
AM Session - 1-2 hours followed by a troubleshooting session
- Process RNAseq data with nf-core/rnaseq pipeline
Day 3
AM Session - 1-2 hours followed by a troubleshooting session
- Analyse processed RNAseq data with nf-core/differentialabundance pipeline
Day 4
AM Session - 2-3 hours followed by a troubleshooting session
- Explore outputs and perform further analyses
Day 1
We will cover:
- Introduction to course.
- Basic Unix.
- Introduction to HAWK.
- Basic Unix Continued.
- Fetch data with nf-core/fetchngs pipeline.
Course Introduction
You should have one of three questions:
- Have you found a nice bulk-RNAseq dataset from a paper and want to download and use it for your research?
- Have you recently generated bulk-RNAseq data and need to process and analyse it?
- You are planning a bulk-RNAseq experiment and would like to know how to process the data when the time comes?
What you will learn on this course:
- How to find and download sequencing data from online data repositories.
- How to process the sequencing data.
- How to analyse the sequencing data.
- How to interpret the analysed data.
What you won’t learn on this course:
- How RNAseq technology/process works. Please see this video for an overview.
- How to hack the mainframe and take over the world.
Basic Unix: Learning Objectives
- Learn the concept of using the command line.
- Learn how to navigate and manipulate files and data.
- Learn how to run and manage programs.
Basic Unix: Brief History
- UNIX is a suite of programs that make up an operating system (like Windows and Mac).
- First developed in 1960’s and has been in constant development ever since.
- It’s a stable, multi-use, multi-tasking system for servers, desktops, and laptops.
- UNIX systems also have a grahpical user interface (GUI), providing an easy to use Windows-like icon-based environment.
- Linux is a clone of UNIX (they’re the same thing). UNIX is a commercial product, whereas Linux is open-source (you can download, install, and use it).
- We will be using Linux on this course.
Basic Unix: Graphical User Interface (GUI) & Command Line/Shell
- All Windows/Mac/Linux PC’s use a GUI to allow users to easily navigate and use the PC.
- The GUI is what allows us to point and click on things, which in turn opens the respective programs etc.
- These operations can also be performed using the command line through the use of a shell.
 This is a shell. We can use this to type commands etc.
This is a shell. We can use this to type commands etc.
Basic Unix: Setup & Installation
- Before we cover installation of Unix on your PC’s, we first need to install the universities VPN.
- We will need to have the Global Protect VPN installed on our PC’s in order to connect to HAWK off campus.
For MAC:
- Use this link and log in to the Software Downloads website with your university log in.
- Then click on Global Protect, then click the MAC OS link, then click on the GlobalProtect-6.2.4.pkg download button to initiate the download to your PC.
- Once the file has downloaded, navigate to it and double-click on it to initiate installation onto your PC.
- Navigate through the installer by clicking Continue.
- Check boxes for GlobalProtect and GlobalProtect System Extensions and click Continue.
- Click Install.
- Enter your admin password when prompted and click Install Software.
- Click Close once the installation has completed.
- When prompted, choose to Allow the system extension in Security and Privacy preferences.
- Click on the system notification to Allow notifications from GlobalProtect.
For Windows:
- Use this link and log in to the Software Downloads website with your university log in.
- Then click on Global Protect, then click the Windows link, then click on the 32- or 64-bit client link. To find out what bit your system is, go to Control Panel > System and Security > System. In the System area, the System Type shows if the system is 32 bit or 64 bit.
- Now click on the GlobalProtect64-6.2.4.msi download button to initiate the download to your PC.
- Click Run to start installation. Accept any browser security messages if they pop up.
- Click Next in the setup wizard and accept the default installation folder on your PC.
- Click Next to install the Agent in the default location in Program Files.
- Click Next to continue with the installation.
- You will be notified once installation has completed, click Close to finish.
Connecting to the VPN:
- The VPN runs automatically after installation.
- Enter the portal address as ras.cf.ac.uk
- Enter your university username and password.
- Click OK when prompted to allow GlobalProtect access to your Desktop, Documents, and Downloads folders (three prompts).
Basic Unix: Setup & Installation: Mac
- Mac users have a built-in Unix shell called bash. To open this, open the Terminal application/program.
- To transfer files to- and from the HAWK servers that we will be using, we can either use code in Terminal (advanced use), or use a file transfer program (FTP) called FileZilla.
FileZilla Installation
- Search for FileZilla on Google, or follow this link.
- Click on the Download FileZilla Client button to initiate the download.
- Once downloaded, double-clicking on the downloaded file will initiate installation.
- Once installed, open the software.
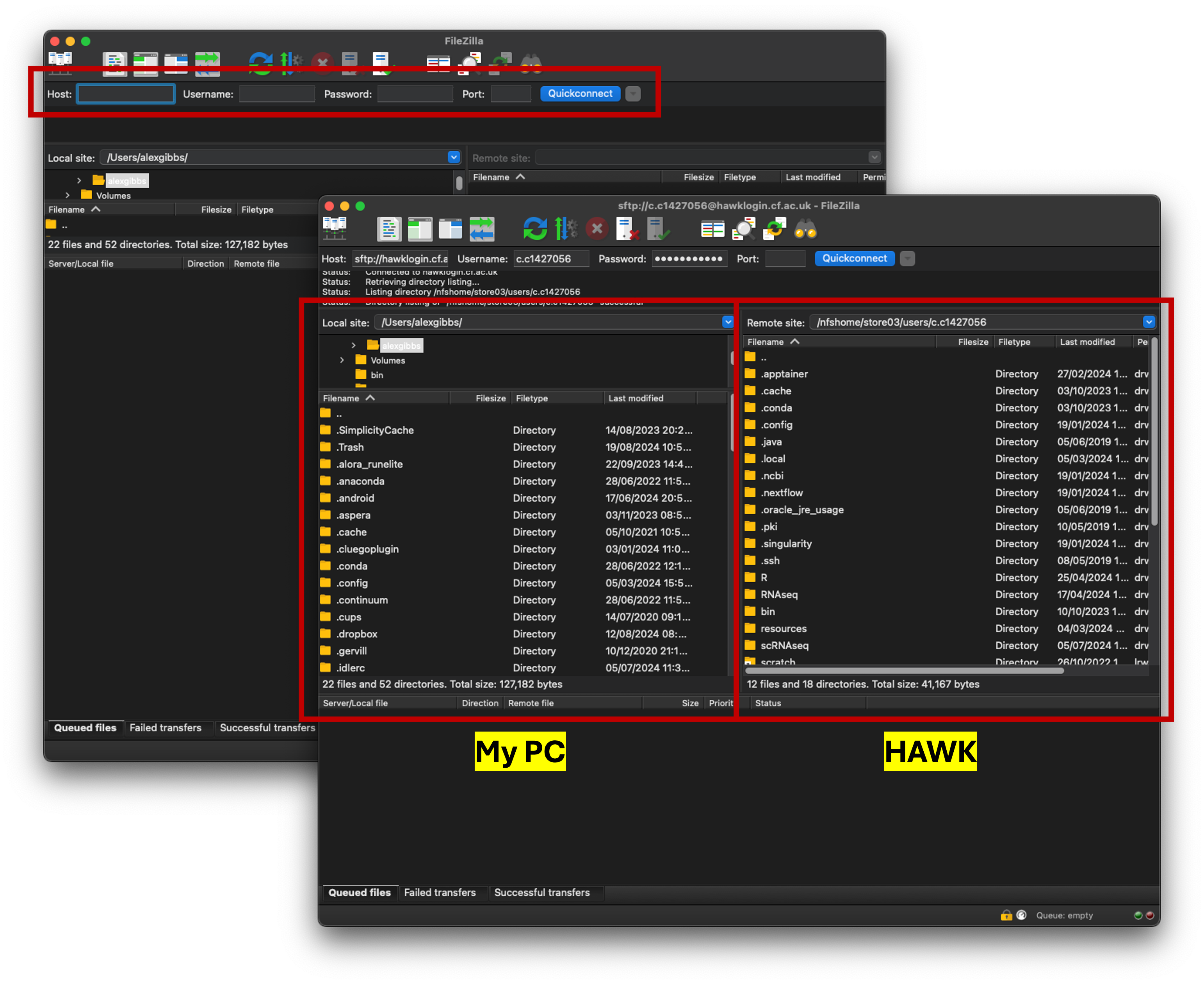
To connect to HAWK:
- Host: hawklogin01.cf.ac.uk
- Username: c.c123456 (Your HAWK account username)
- Password: XXXXXXX (Your HAWK account password)
- Once connected, you will see that you have two connections.
- Your PC files and folders are on the left box.
- Your HAWK files and folders are on the right box.
- To transfer files, simply drag and drop from one side to the other.
- You can also double-click on the respective folders to navigate to wherever you want to be.
Basic Unix: Setup & Installation: Windows
- Windows users don’t have an integrated Unix shell, so you will need to download and install one. We will use MobaXterm.
- MobaXterm is an integrated shell, which combines command line with FTP all in one window/application.
- Mac users have a built-in Unix shell called bash. To open this, open the Terminal application/program.
- To transfer files to- and from the HAWK servers that we will be using, we can either use code in Terminal (advanced use), or use a file transfer program (FTP) called FileZilla.
MobaXterm Installation
- Search for MobaXterm on Google, or follow this link.
- Click on the Download Now button on the Home Edition version to initiate the download.
- Once downloaded, click Run to initiate installation.
- Once installed, open the software.
THIS BIT NEEDS COMPLETING
MAKE SURE TO INCLUDE HAWKLOGIN01 TO TAKE USERS TO CL1 NODE!
Introduction to HAWK
- HAWK is Cardiff and Bangor universities High Performance Compute (HPC) system.
- Swansea and Aberystwyth universities use SunBird - both systems are the run by Supercomputing Wales (SCW).
- Both HPC’s are the same, but are set-up slightly different - we will be working with HAWK.
- If we need to run analyses/softwares/code that requires a lot of computing power, we need to use HPC’s.
- The way we interact with HAWK is through the command line via Bash.
- Think of HAWK as a computer that’s located in the cloud. We can connect to it via out Unix shells - Terminal, MobaXterm, and FileZilla.
Introduction to HAWK: HAWK Filesystem
- Like our own PC’s, HAWK has its own files and folder structure.
- From here, we will now refer to folders as directories.
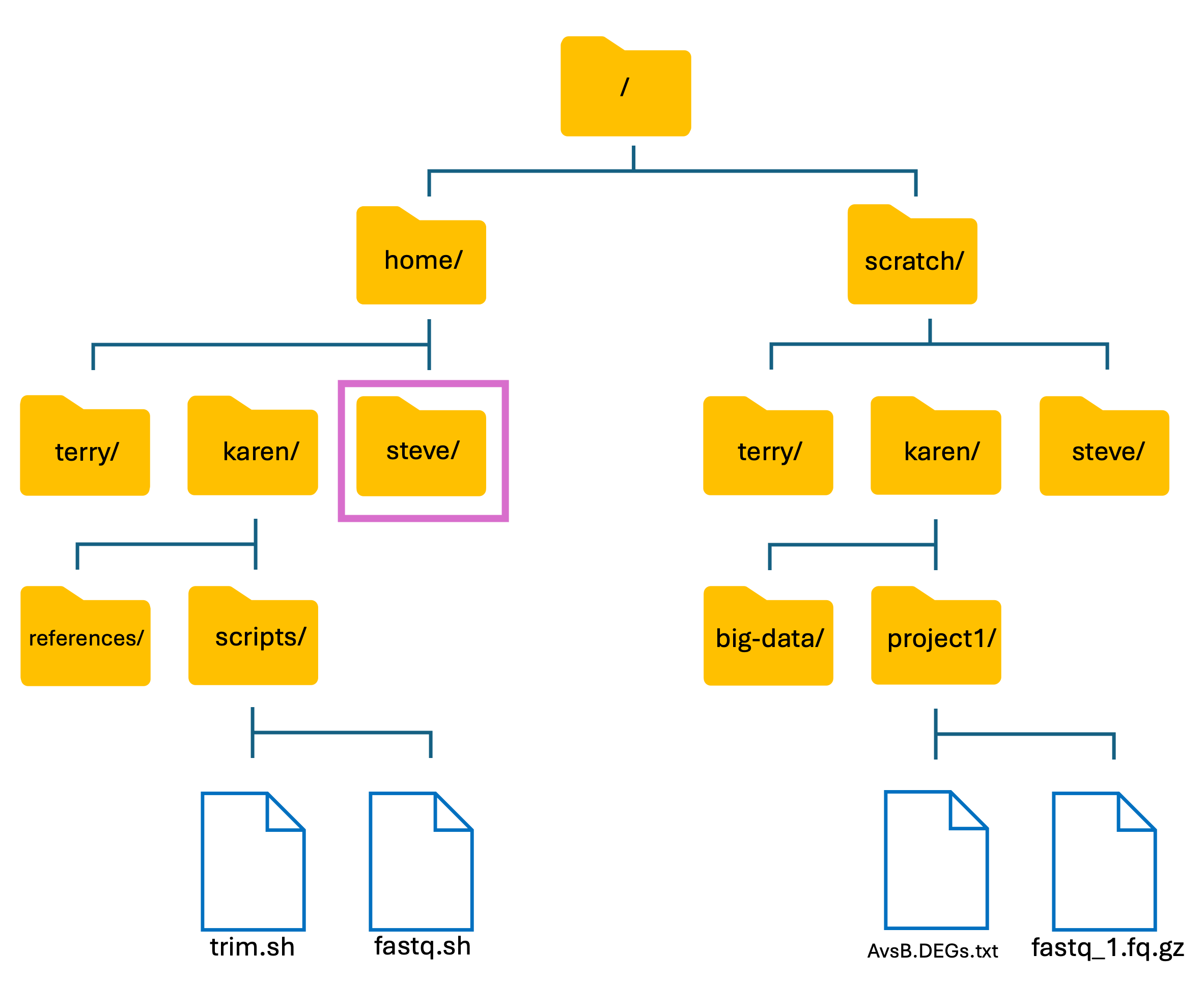
- The basic structure of HAWK:
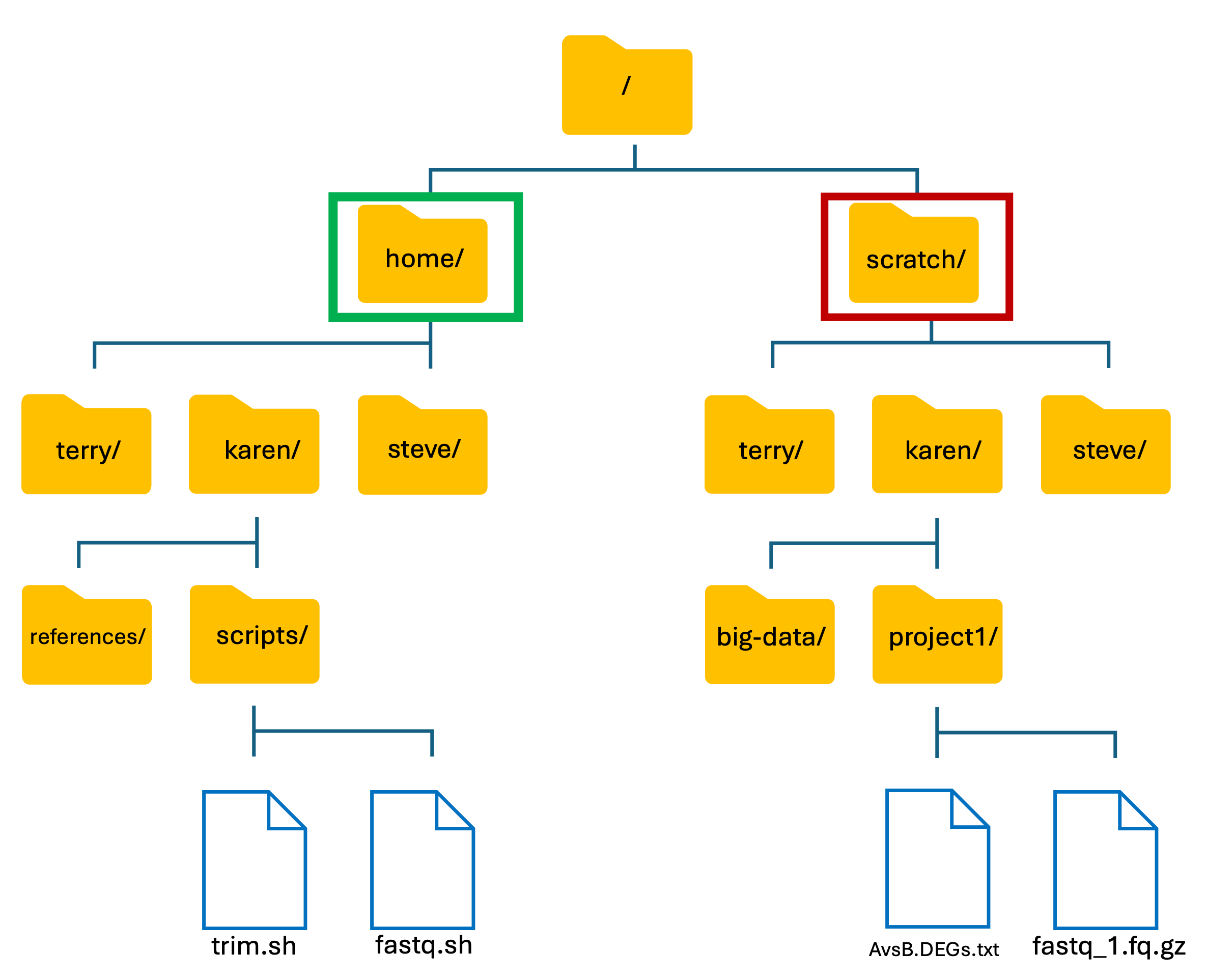
-
We have two main directories: home and scratch.
- home directory
- This is where we are located when we log into HAWK.
- Has limited long-term storage.
- DO NOT WORK HERE!
- scratch directory
- This is where we perform our compute-heavy analyses.
- Not for long-term storage! Files are deleted after 60-days.
- Do your work, then move your files back to home directory or to another storage location such as the Research Data Store (RDS).
Basic Unix Continued: Common Commands
-
Now that we have covered basic Unix and introduced HAWK, we can now learn how to use the command line.
-
Here is a list of commonly used Unix commands that we will be using:
| Command | Description | Common Options | Option Description |
|---|---|---|---|
ls |
print directory contents | ls -lah |
list that is long, shows hidden files, and is human-readable |
mv |
rename/move a file | mv -r/* |
moves recursively (moves a directory and everything inside)/moves everything |
cp |
copy a file | cp -r/* |
copies recursively (copies a directory and everything inside)/copies everything |
cd |
change directory | ||
pwd |
where am I? | ||
history |
what have I typed? | ||
rm |
remove a file | rm -r/* |
removes recursively (removes a directory and everything inside)/removes everything |
mkdir |
make a directory | ||
touch |
make an empty file | ||
nano |
open and edit a file | ||
more/less |
reads a file | ||
head |
read the top of a file | ||
tail |
read the bottom of a file | ||
wc |
count the number of lines in a file | ||
grep |
word search in a file | ||
chmod |
change permission of a file | chmod +x |
makes file executable |
Basic Unix Continued: Command line Syntax
Syntax = Structure of statements in a computing language.
“I like computers” - pronoun, verb, noun
ls -lah . - command, options, arguments
ls= list command-lah= options for the list command.= argument for the list command
All commands are case sensitive!
Command
- The
lscommand will list/print the files and directories in your current directory.
Options
- The
-lahoptions will print a list in long format which will be human readable and show hidden files.
Argument
- The argument gives the system the required input, these are usually files or directories
- The
.argument means ‘here’ or where I currently am. We will cover this shortly.
Not all commands have options, and most commands have optional options - you don’t have to use them!
Basic Unix Continued: Exploring Using Unix
- Lets cover the three most basic (and used) commands:
pwd= Where am I?ls= Listcd= Change directory
Basic Unix Continued: pwd Command
- When we first open a Unix shell, we are taken to the default directory.
- If you have downloaded a shell (such as iTerm2, MobaXterm, FileZilla), this location can change depending on where you installed the software.
- To find out where we are currently located, we can use the
pwdcommand. - In the example below, the pwd output tells me that I am in my Desktop directory.
Input
pwd
Output
/Users/alexgibbs/Desktop

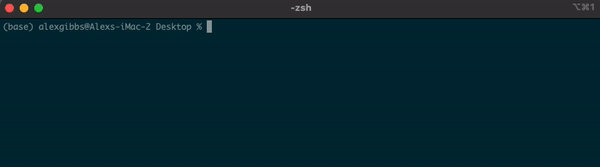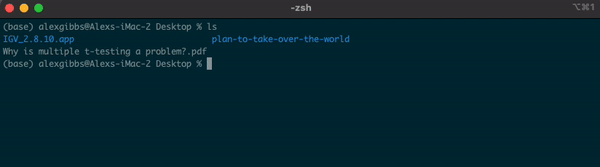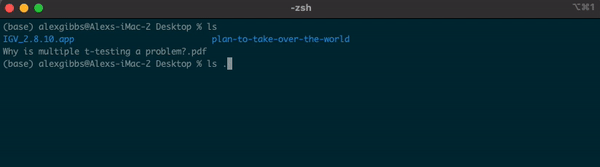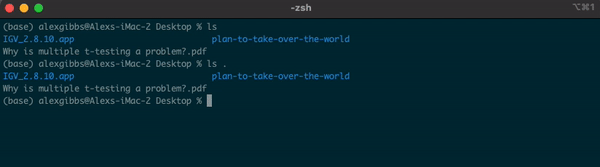
Basic Unix Continued: ls Command
- To explore the directory, we can use the
lscommand to list the contents of the Desktop directory:
Input
ls
Output
IGV_2.8.10.app plan-to-take-over-the-world Why is multiple t-testing a problem?.pdf

- To see this list in a long format, we can use the
-loption. - To see hidden contents, we can use the
-aoption. - To see the contents in a human-readable format, we can use the
-hoption. - In the example below, we combine both options to return a long, hidden, and human-readable list of contents:
Input
ls -lah
Output
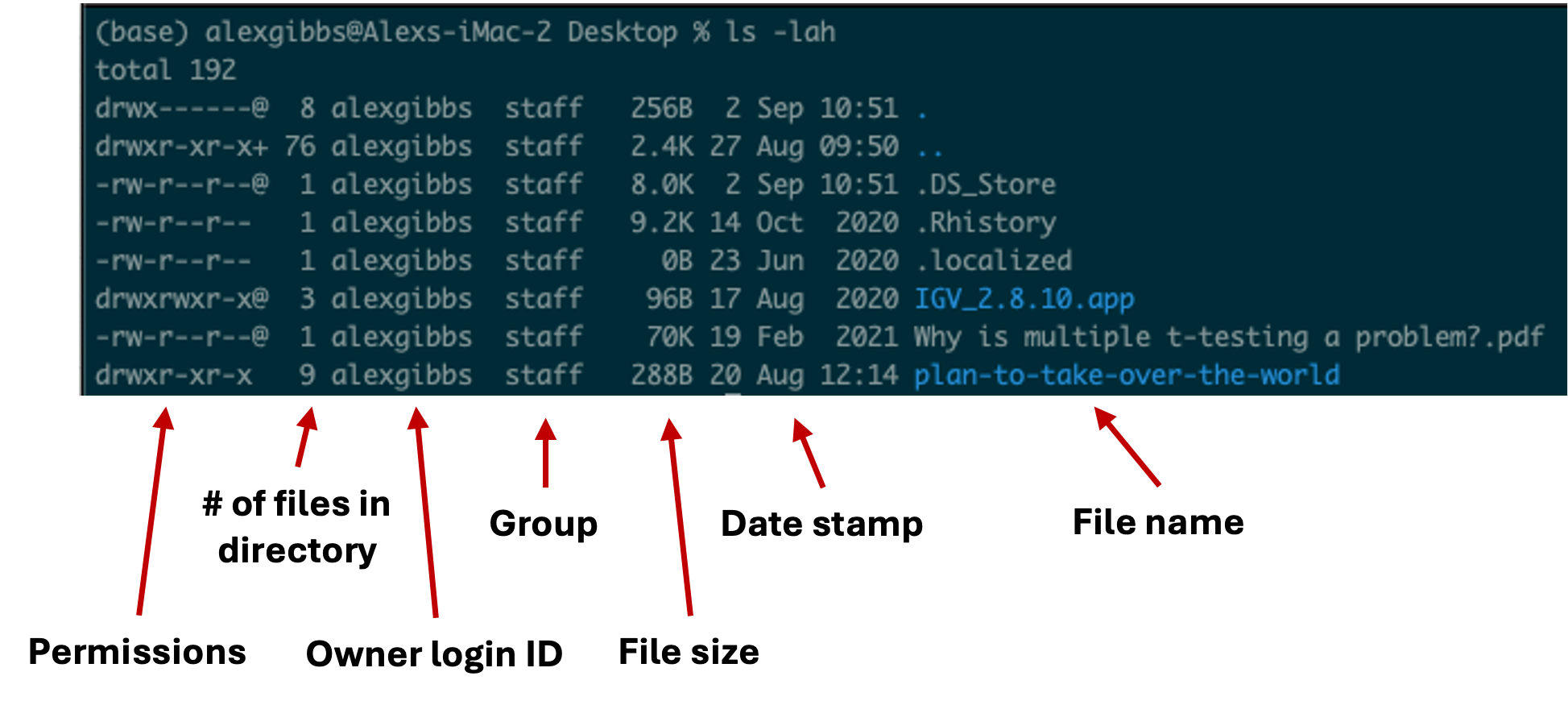
- We will cover permission shortly
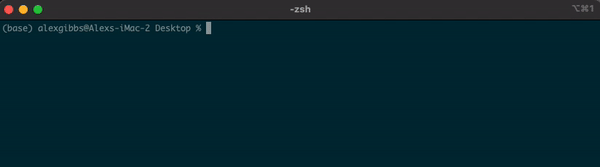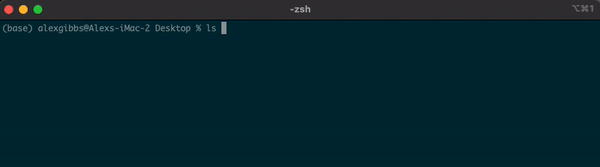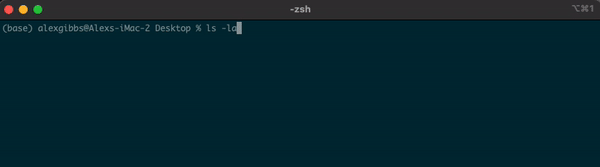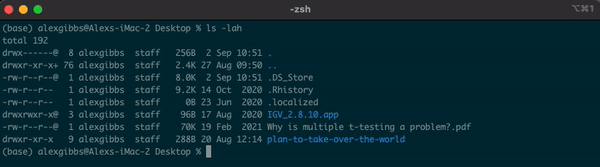
- Any file or directory with a dot (.) in front makes it hidden.
- Hidden files are usually filesystem files and directories required by the system to correctly operate and function.
- These hidden files are not normally needed by the user. \
- In this course, we will potentially need to access a hidden file if things go wrong.
Basic Unix Continued: cd Command
- To move between different directories, we use the
cdcommand. - In the example below, we move into the plan to take over the world directory.
- Note: we can use the
tab-keyto autofill. Start typing the name of the directory and then hit tab. - Note: when we use the
cdcommand, we don’t get any feedback from the shell. Usually, we move into the directory, then use thelscommand to show us the contents.
Input
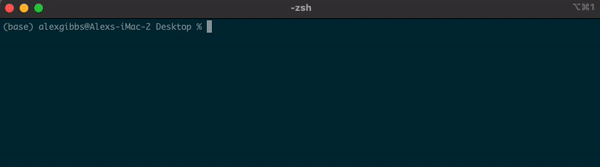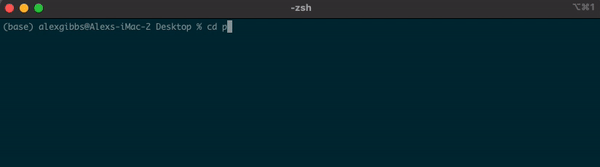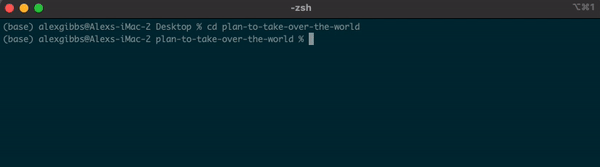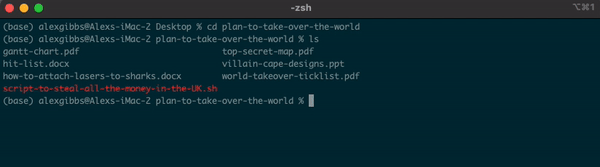
cd plan-to-take-over-the-world
ls
Output
gantt-chart.pdf top-secret-map.pdf
hit-list.docx villain-cape-designs.ppt
how-to-attach-lasers-to-sharks.docx world-takeover-ticklist.pdf
script-to-steal-all-the-money-in-the-UK.sh
Basic Unix Continued: Other Notations
Tab-key
- As mentioned above, we can use the
tab-keyto autofill. - This will save you time and lots of errors! The
tab-keyis your friend!
Making Use Of The Dot(.)
- As mentioned above, the dot(.) is used to tell the system where you currently are.
- This is best used for commands such as
lsandcd. - When we combine two dots(..), this tells the system to use the directory above where we currently are.
| Input | Description |
|---|---|
| . | Here/where I am now |
| .. | Previous directory/up one directory |
-For example, if I am currently in the Desktop directory and want to list contents of where I currently am, I can either use ls or ls .
Input
ls
ls .
Output
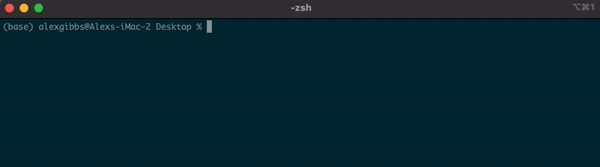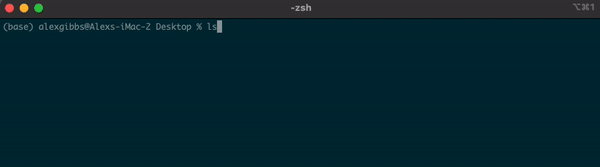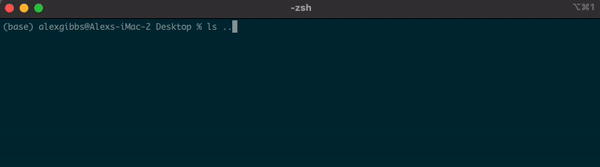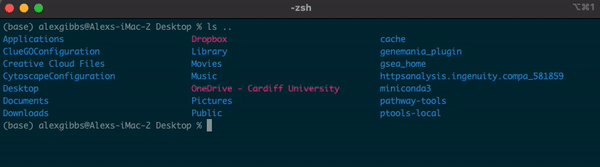
- If I wanted to see what contents were above/outside of my Desktop, I would use
ls ..
Input
ls ..
Output
Wildcard (*)
- The wildcard (*) can be used to select multiple things at once.
- It is used to match any character and is commonly used to select directories/files with common names.
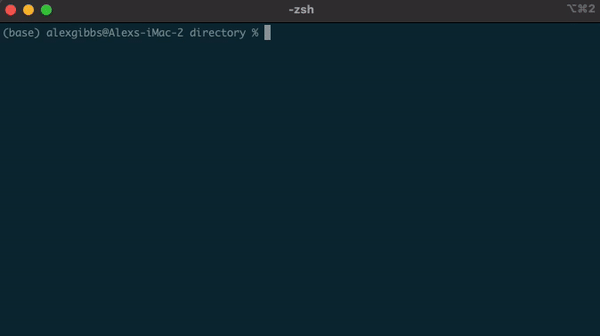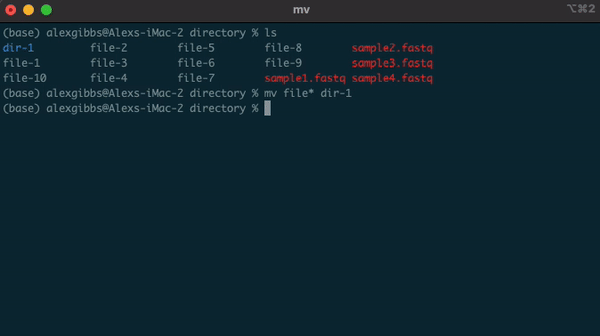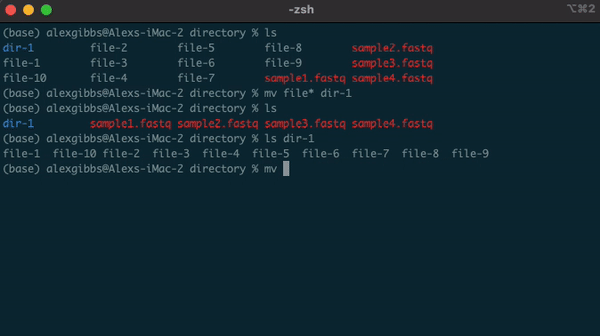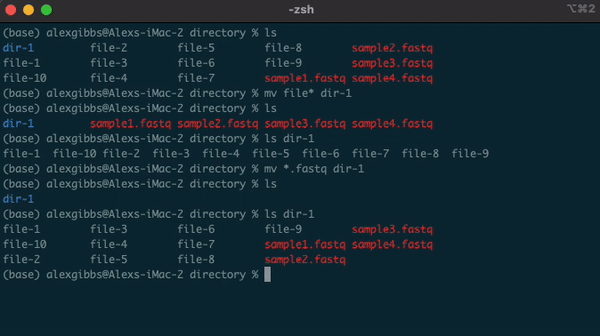
- Example, if there are multiple directories (file-1 through file-10) and I wanted to move them all into one directory (dir-1), I could use the common name to all the files followed by the wildcard.
mv file* dir-1/- The wildcard can also be used to select the same file extensions. Example: If we wanted to move all the .fastq files to a new directory, we would use the wildcard followed by the extension.
mv *.fastq dir-1/
Input
ls
mv file* dir-1/
ls dir-1/
mv *.fastq dir-1/
ls dir-1/
Output
Basic Unix Continued: Working Example
-
To give a visual explanation of what we have covered so far, let’s use the HAWK directory structure that I made up:
-
I have just logged into my HAWK account and am not sure where I am located. To find out, I used the
pwdcommand. This tells me that I am in the home directory:
Input
pwd
Output
/home/steve
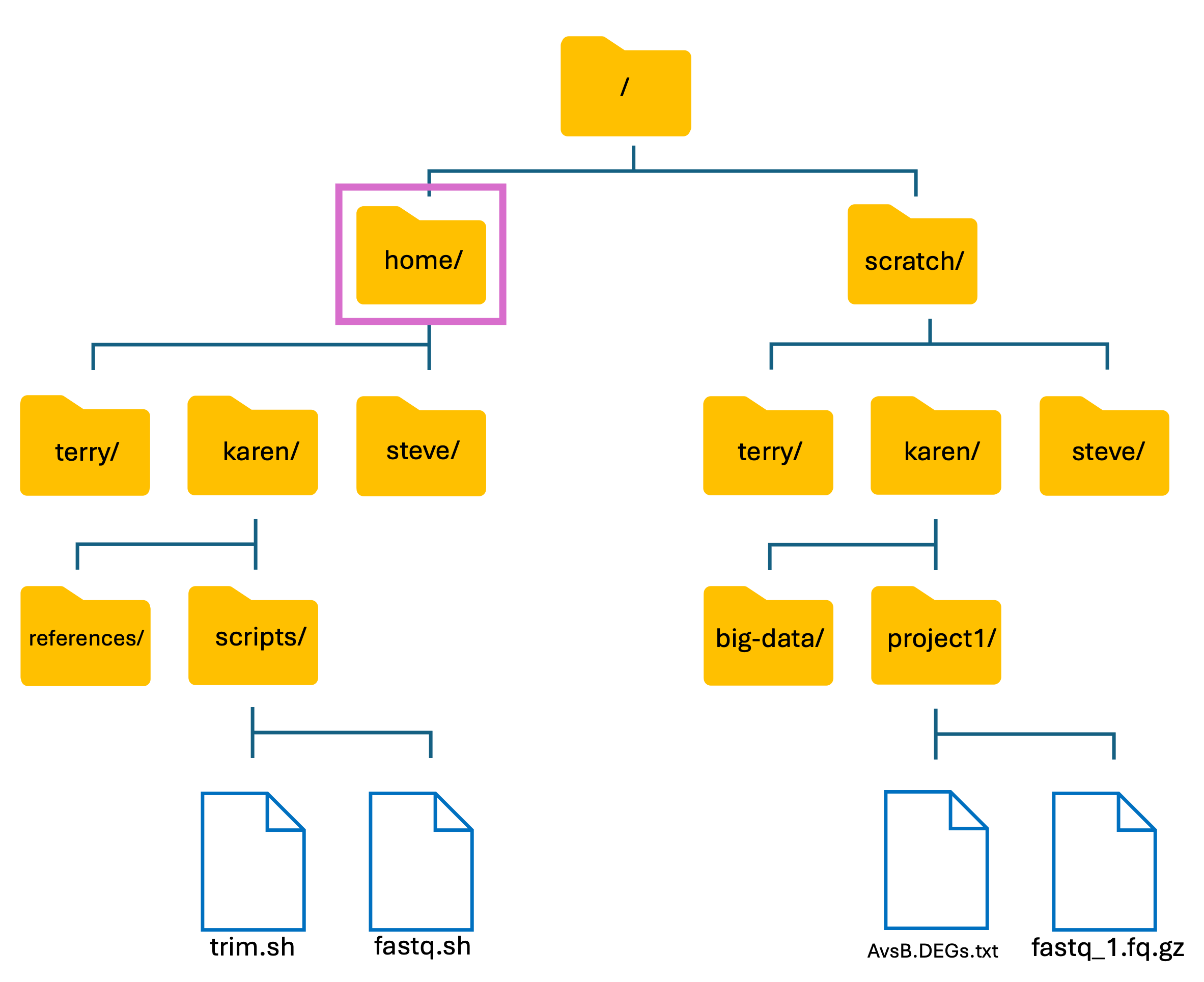
- One of the SCW administrators told me that a few users had used my account for training purposes and stored some files etc. Lets first see if the users made a directory in the home directory:
Input
ls ..
- This command lists the contents in the directory above mine, i.e. lists the contents of the home directory
Output
karen steve terry
- I decided to look at what Karen had been up to in the home directory.
- Theres two ways to do this, either move into her directory and list the contents, or use the list command.
Input
ls ../karen
OR
cd ../karen
ls
- Note: As I am still in my directory, I need to use the two dots (..) to move up/out and then into Karens directory.
Output
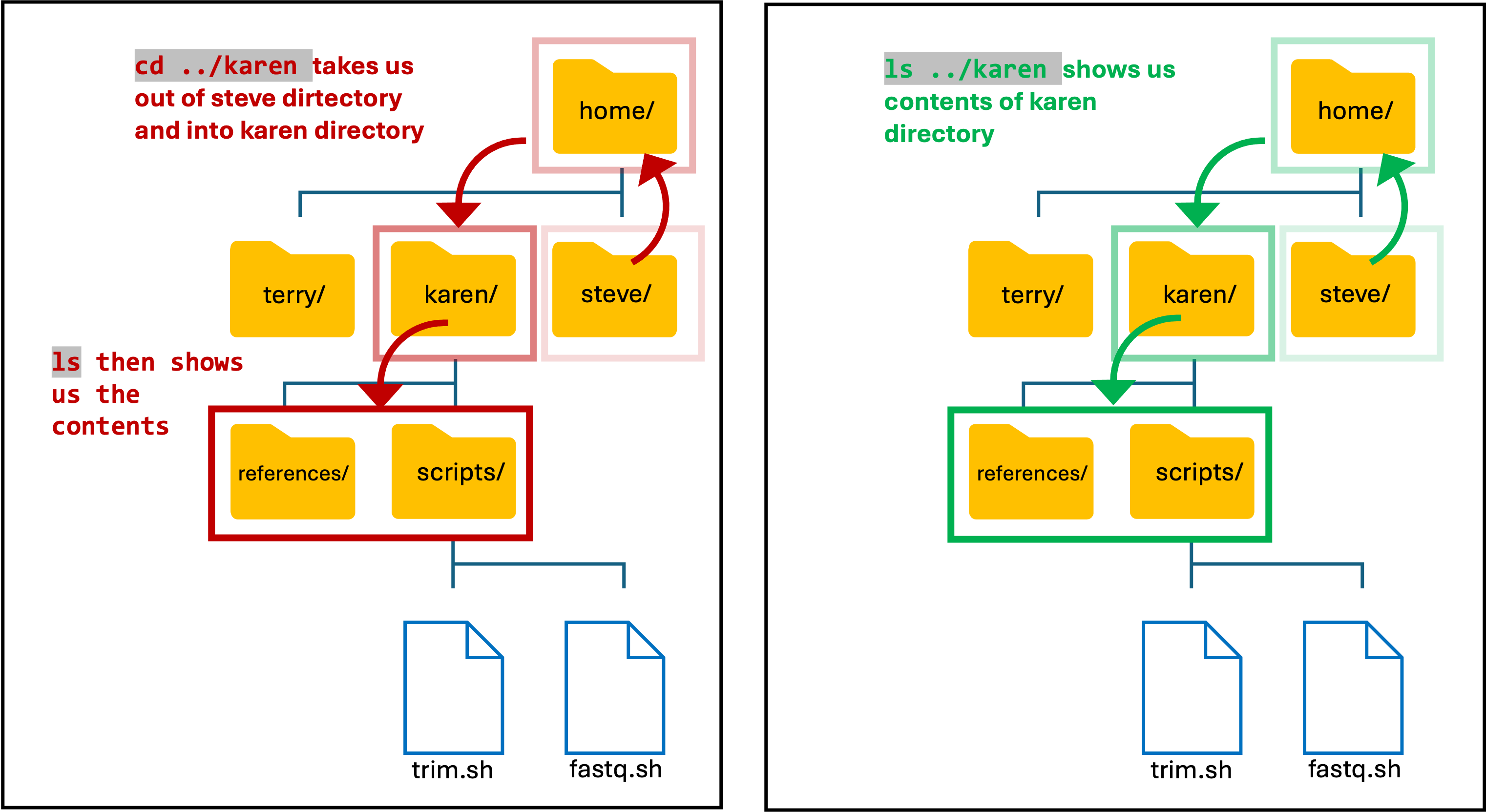
This Needs To Be Completed!
Basic Unix Continued: File Permissions & File Privacy
- File permissions determine who can and who can’t access certain files and directories.
- On HAWK, each user has their own account which comes with their own home and scratch directory.
- These directories can only be accessed by the user (and the admins). Other users can see that you have a directory, but cannot access as they do not have permission to do so.
- To see the file and directory permissions, we must first understand how the permissions are ordered.
- Unix splits file permission into three sections:
| Section | Description |
|---|---|
| user | The file/directory owner |
| group | A group of individuals permitted to read the file |
| other | Everyone |
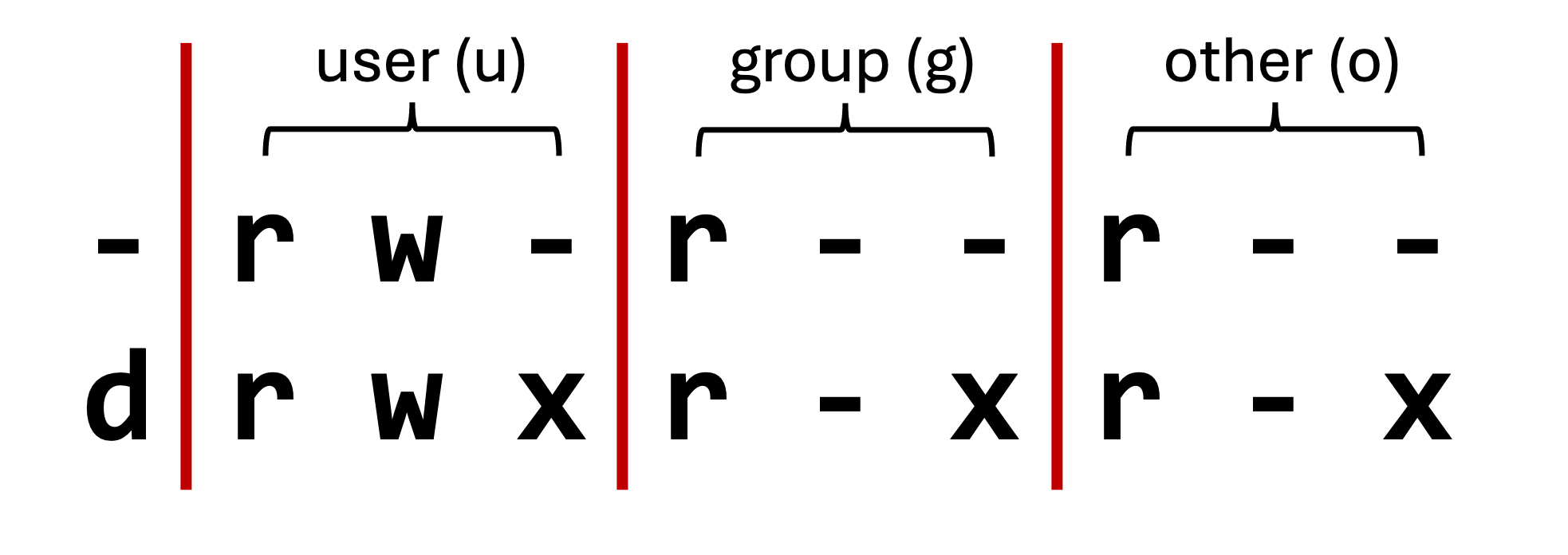
| Symbol | Meaning |
|---|---|
| -/d | file/directory |
| u/g/o | user/group/other |
| +/- | enable/disable |
| r/w/x | read/write/execute |
- The group section enables group access to files and directories.
- When we run scripts, we need to make sure they are executable (x), otherwise the system will not recognise it as an executable file.
- To check if a file is executable, we can use the
ls -lcommand and check the permissions.
Changing File Permissions
- A good example for changing file permissions is to make a script executable.
- In the example below, I have made a shell script named file-permission.sh
- These types of files (.sh) are what we use to run a script on Unix. These scripts can range from a simple one liner task, to a list of tasks that will run sequentially.
- When we create a file using the
touchornanocommand, by default it is not executable, as denoted by-rw-r--r--. We will covernanoshortly. - Subsequently, the system does not recognise it as an executable file and you wont be able to run it.
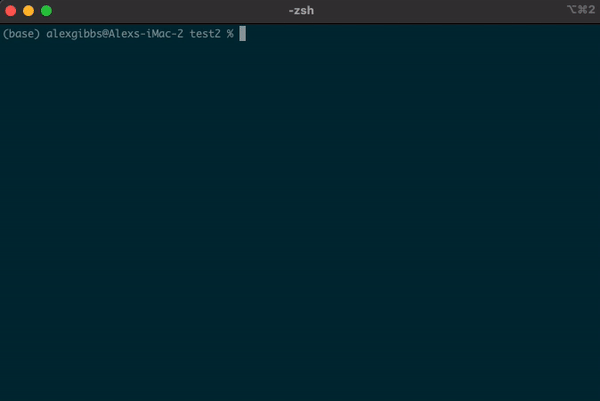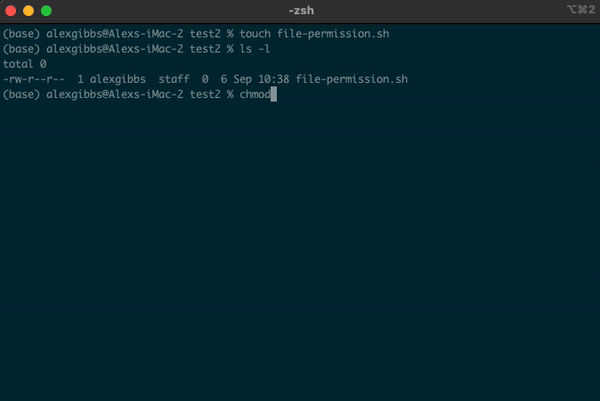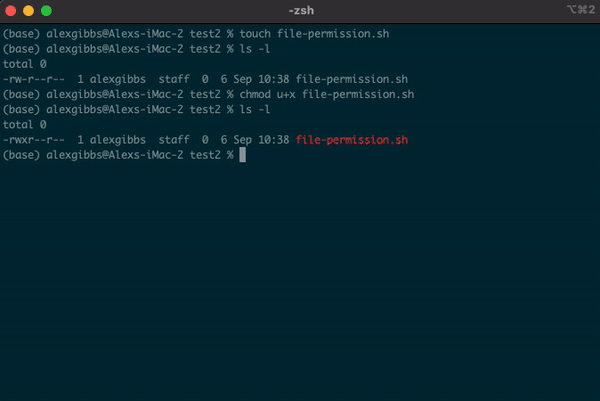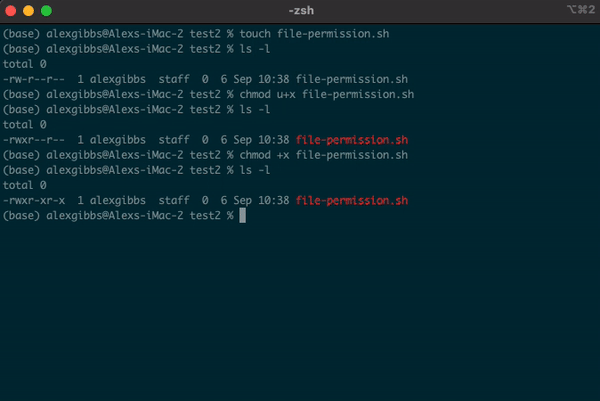
- To change the file permissions and make the file executable, we use the
chmodcommand. - If we wanted to change the permission for just the user (u), we would use
chmod u+x. - Using
chmod +xon the file makes the file executable (x) for everyone (u/g/o).
Input
touch file-permission.sh
ls -l
chmod +x file-permission.sh
ls -l
Basic Unix Continued: Moving & Copying Files
- We sometimes will want to copy or move files from one directory to another.
- An example of this would be copying a reference genome from our home directory (long term storage) to our scratch directory for an analysis.
Basic Unix Continued: Copying a file using cp command
- The copy command does what it says on the tin… Copies a file/directory from one place to another.
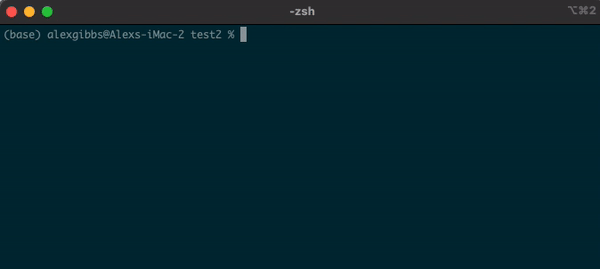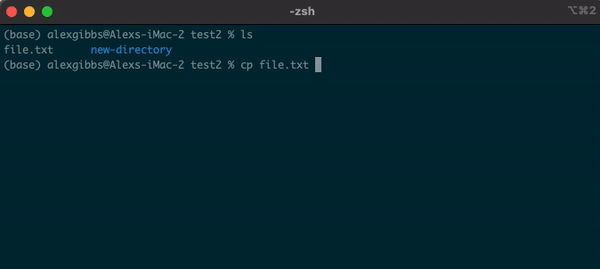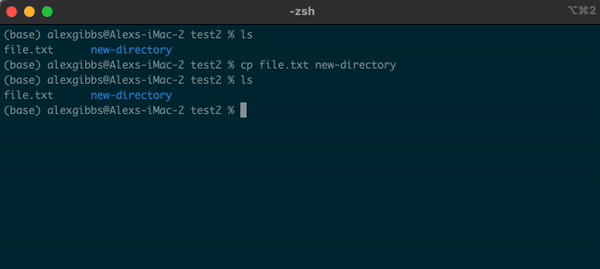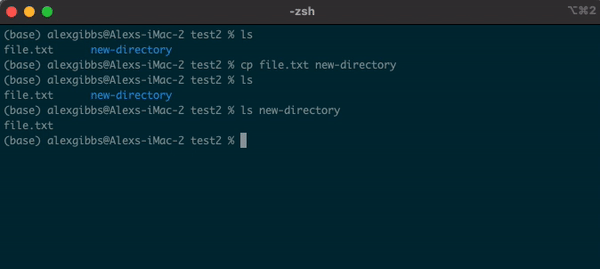
Input
cp name-of-file.txt path/to/directory/
- The command works by first inputting the name of the file/directory that you want to copy, followed by the location of where you want to copy it to.
- To copy a directory, we need to use the
-roption:
Input
cp -r name-of-directory path/to/directory/
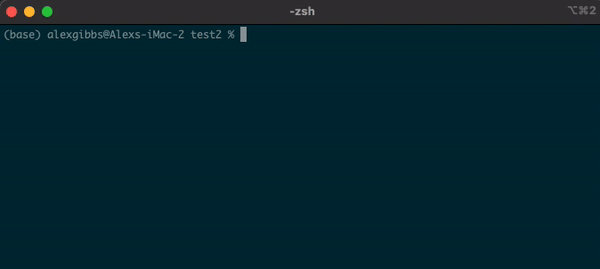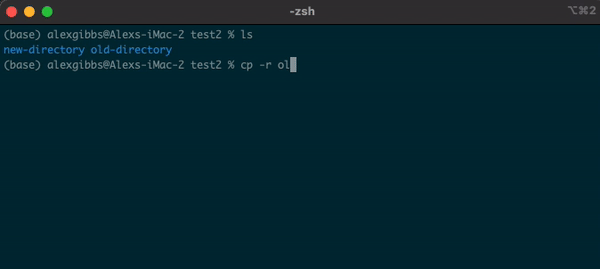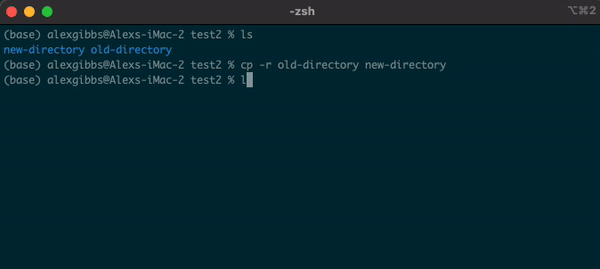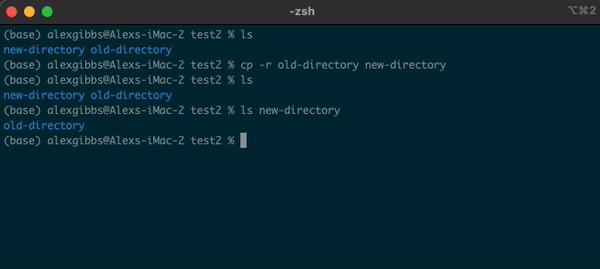
- To state the obvious, this command makes a copy of the file at the destination that you have chosen.
Basic Unix Continued: Moving a file using mv command
- The move command does what it says on the tin… Moves a file/directory from one place to another.
Input
mv name-of-file.txt path/to/directory/
mv name-of-directory path/to/directory/
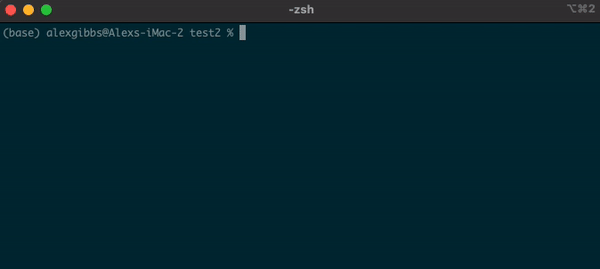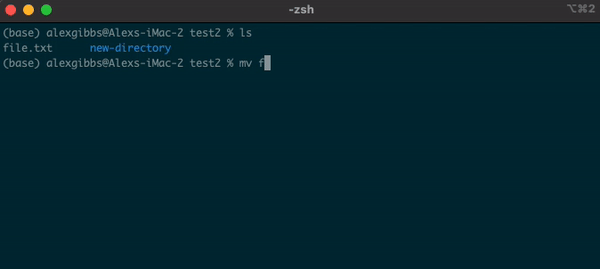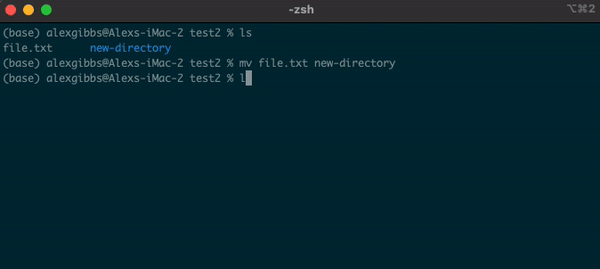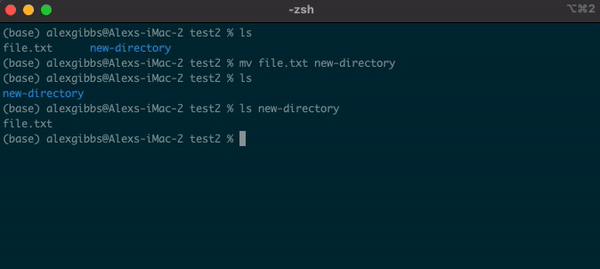
- The command works by first inputting the name of the file/directory that you want to move, followed by the location of where you want to move it to.
- Note: This command physically moves the file/directory to the location you have chosen. Be aware of typos when using this command, as it is very easy to overwrite other files/directories!
- I would reccomend sticking to using the cp command when you want to move files just in case you make typos
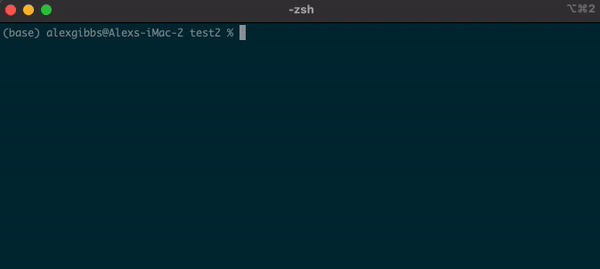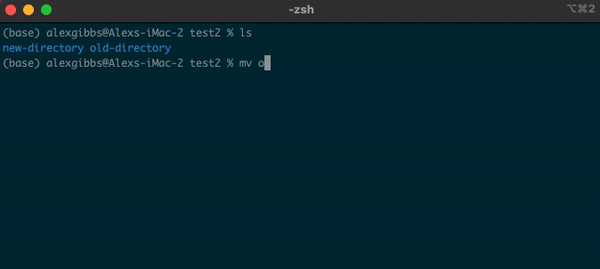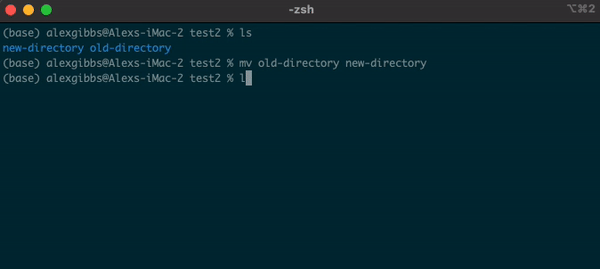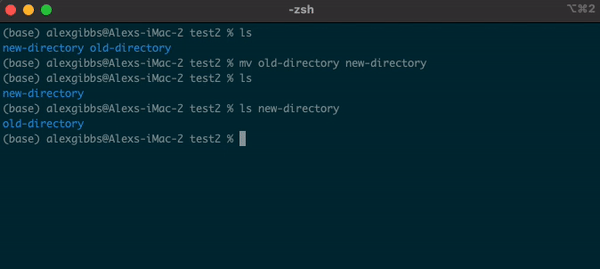
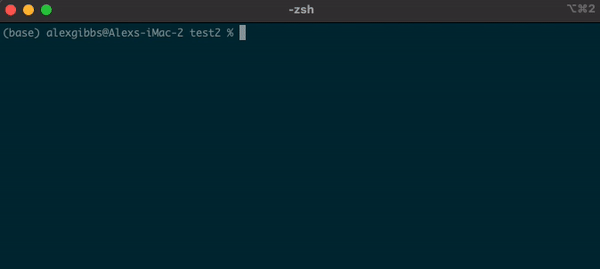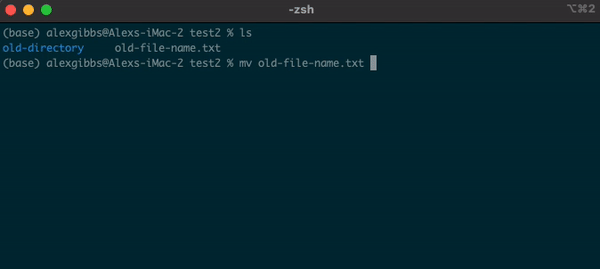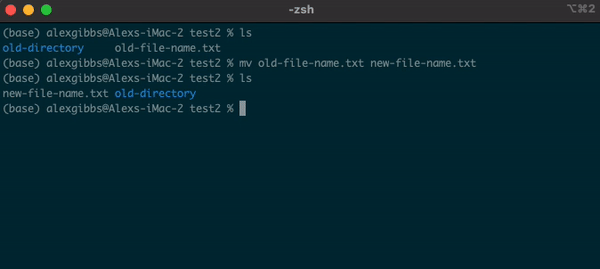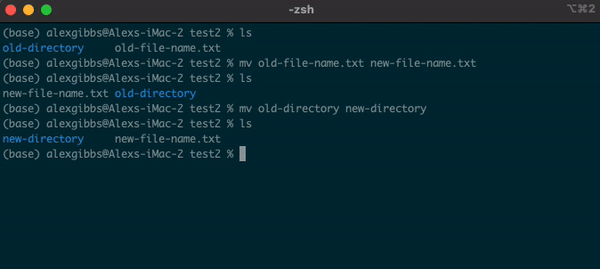
- The
mvcommand can also be used to rename a file/directory:
Input
mv name-of-file.txt new-name-of-file.txt
mv name-of-directory new-name-of-directory
Basic Unix Continued: Making a file
- To make a file, we can use the
touchcommand. - We don’t need to use this command for the course, but for completeness (and for the task ahead) we will cover it.
Input
touch name-of-file.extension.name

- The command works by calling the
touchcommand followed by the name and extension of the file you want to create. - To make a file named
myFile.txt, we would usetouch myFile.txt.
Basic Unix Continued: Editing a file
- To edit a file in Unix, we can use an editor called nano.
- The nano editor opens a new window within the Unix shell whilst in use, and then returns you to where you was once you have exited the editor.
- To use the editor, we simply use the
nanocommand. - The editor can be used to create new files and also edit existing files.
- If we wanted to create a new file, we would use
nano name-of-new-file.extension.name. - Likewise, if we wanted to edit an existing file, we would use
nano name-of-existing-file-extension.name. - To exit the nano editor, use
ctrl + x, thenyto save, thenenterto exit.
Input
nano myFile.txt
this is some simple text that I want to put into the file.
this another simple line of text to include.
ctrl + x
y
enter
- Along the bottom of the editor, you can see the various options that you are able to use.
- Once we use
ctrl + xyou can see the bottom of the editor changes tosave modified buffer?. TypingYsaves the file,Ndeletes it. - Once you have hit
Y, you get another prompt to check the file name. Here, you get the opportunity to rename the file if needed. Then hittingentersaves and exits the editor.
Basic Unix Continued: Making a directory
- To make a directory, we can use the
mkdircommand.
Input
mkdir name-of-directory
- The command works by calling the
mkdircommand followed by the name of the directory you want to make. - We can use this command to make multiple directories within the current directory, too:
Input
mkdir directory1 directory2 directory3
- Each new directory is named after the other and is separated by a space whilst using the command.
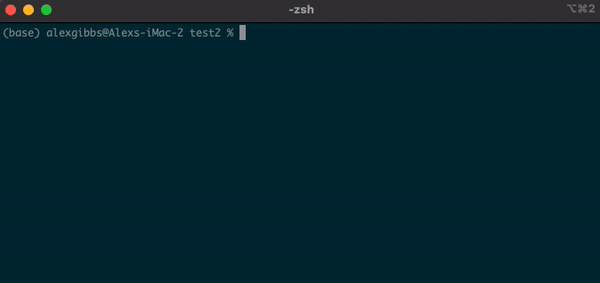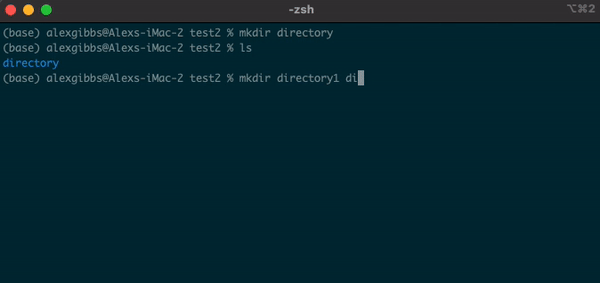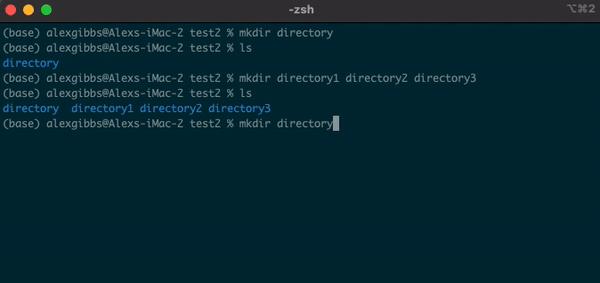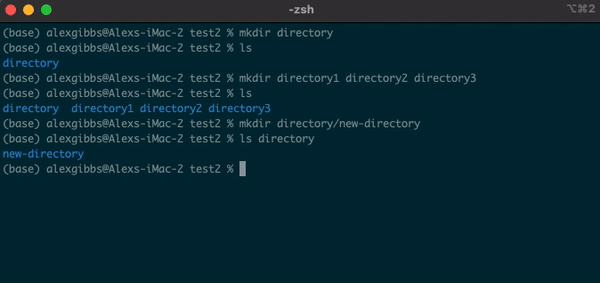
- We can also create a new directory within an existing directory without moving into it:
Input
mkdir directory1/directory1.1
- The
touchcommand can also be used in this manner.
Exercise 1
- Open a shell on your PC.
- Find out where you are.
- Find where the unix-practical directory is.
- Move into the unix-practical directory and list the contents.
Answer
Find out where you are:
pwd
List contents:
ls
Change directory:
cd unix-practical
The unix-practical directory should be located within your Downloads directory (unless you have moved it)
pwd
ls /Users/c1234567/Downloads
cd unix-practical
ls
Exercise 2
- Map out the unix-practical directory.
- Are there any hidden files?
Answer
List the contents:
ls -lah
List contents of the ascii directory:
ls -lah ascii
update this code
update this code
update this code
update this code
nf-core/fetchngs Pipeline
- nf-core is a community effort to collect a curated set of analysis pipelines that are built using Nextflow.
- The nf-core website contains >100 curated pipelines and is used by thousands of researchers and bioinformaticians across the globe.
Add a more punchy explanation and importance of why we should be using nf-core.
- Nextflow is a tool that allows us to run several different tasks on HAWK.
- Each task may depend on an output from a previous task, may need to be run sequentially, or perhaps need to be run individually all at once.
- Nextflow allows us to do this, and helps organise the way these tasks are run.
Fetchngs Pipeline
- This pipeline allows us to fetch metadata and raw FastQ files from public and private databases
- The pipeline currently supports SRA/ENA/DDBJ/GEO/Synapse IDs.
- The only thing we need for this pipeline to run is a list of sample IDs.
Finding a dataset
- We first need to find a dataset. Some of you may already have found one via a paper that you have read etc.
- There are multiple repositories that we can find samples on. The two most common are Gene Expression Omnibus (GEO) and Array Express.
- For this course, we will use GEO to find our dataset.
GEO
- When accessing the GEO website, we are faced with multiple links and tools.
- If we have a dataset in mind that we would like to find, we can use the search bar at the top right of the page.
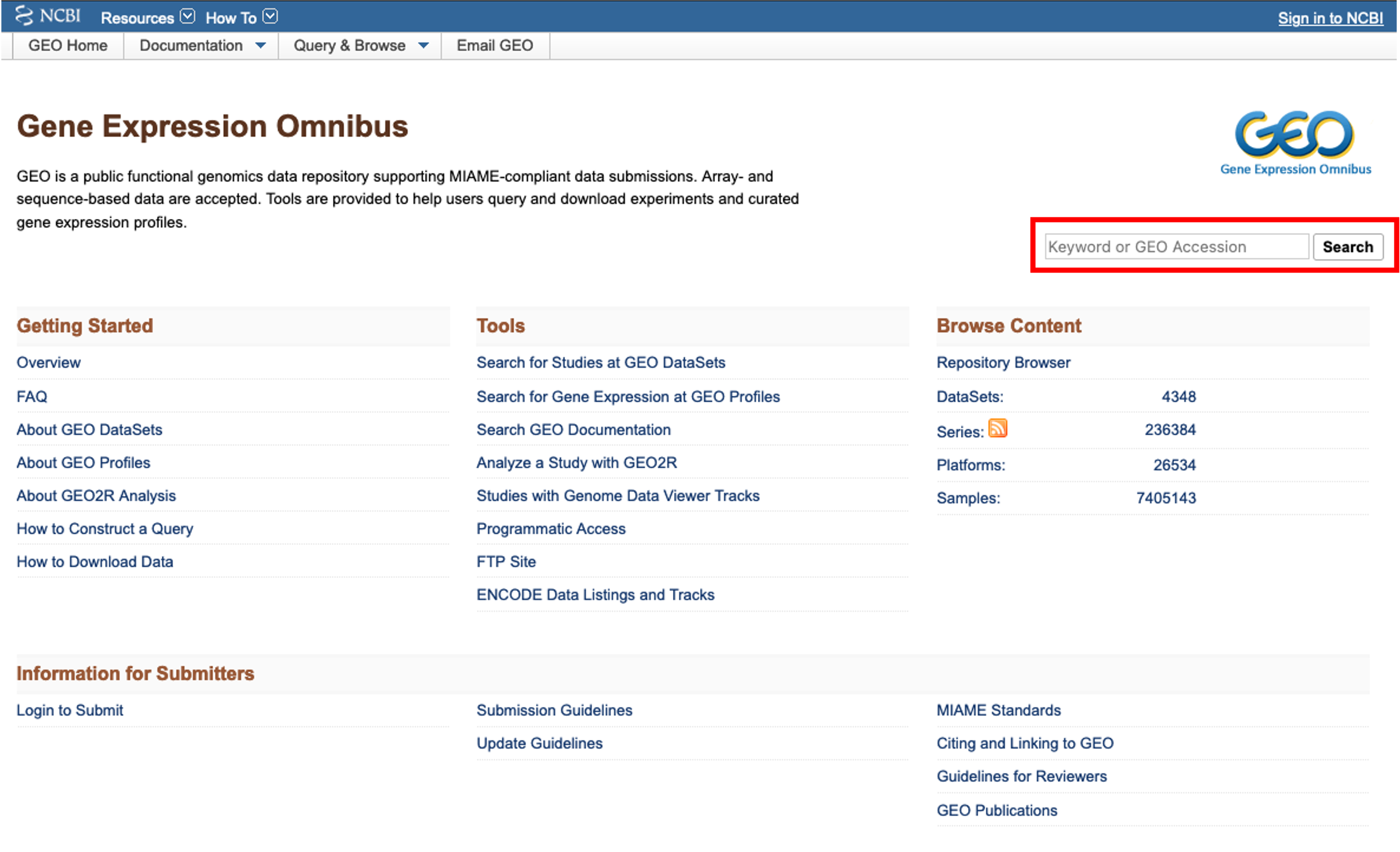
- I would like to find a bulk rna seq dataset on renal cell carcinoma. To do this, I enter ‘renal cell carcinoma rna seq’ into the search bar and click ‘search’.
- A pop-up window appears telling me that there are 351 results. Clicking on the ‘351’ will load the results.

- On the results page, we are greeted with the results accompanied by further optional filters on the left and right hand side of the page.
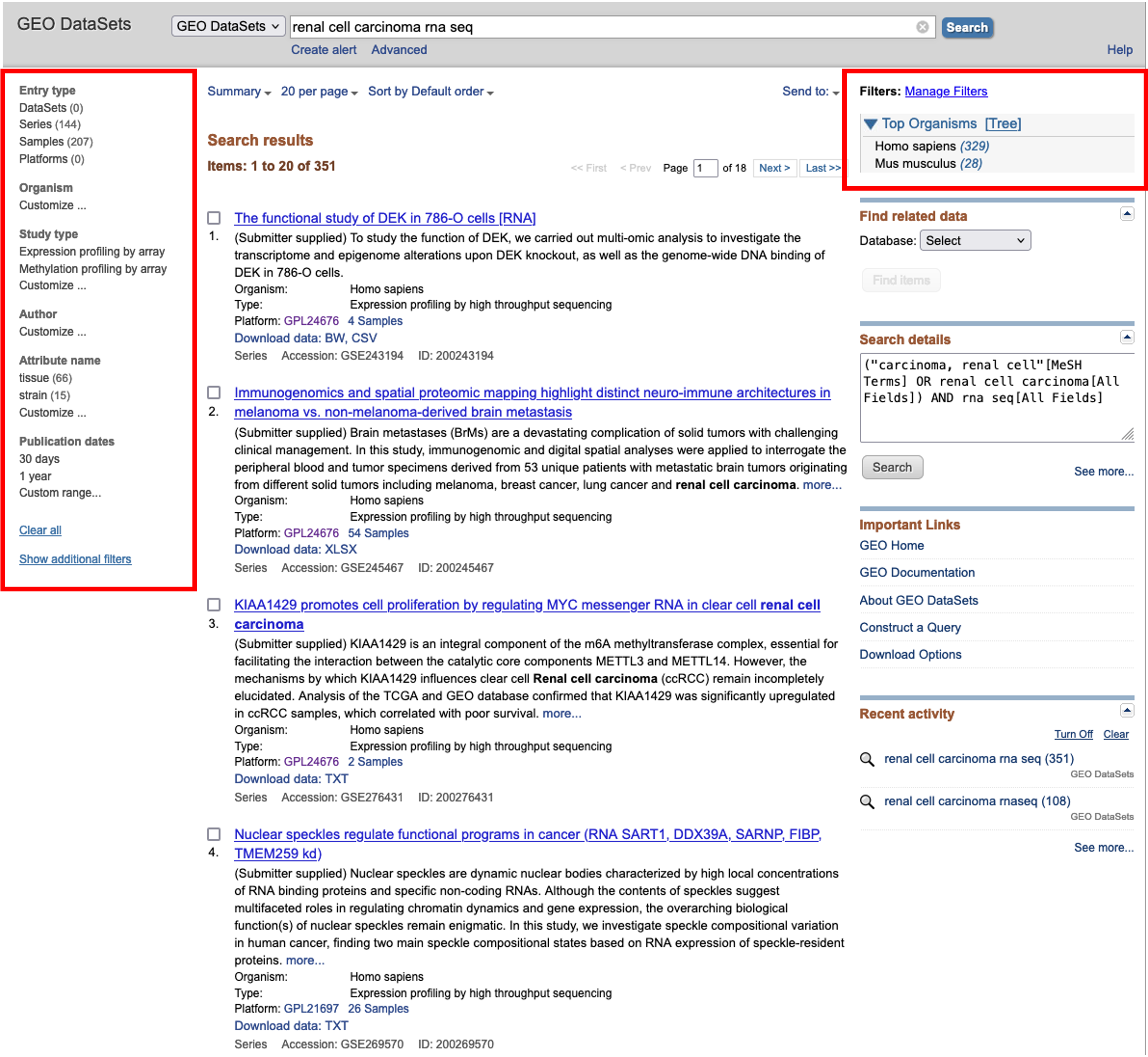
- Here, we will choose to filter for Homo sapiens using the option on the right hand side and then browse for an interesting dataset.
- For this course, I found a nice dataset looking at the effects of hypoxia on gene expression across two different cell lines.

- Clicking on the dataset title will load the series record for that dataset.
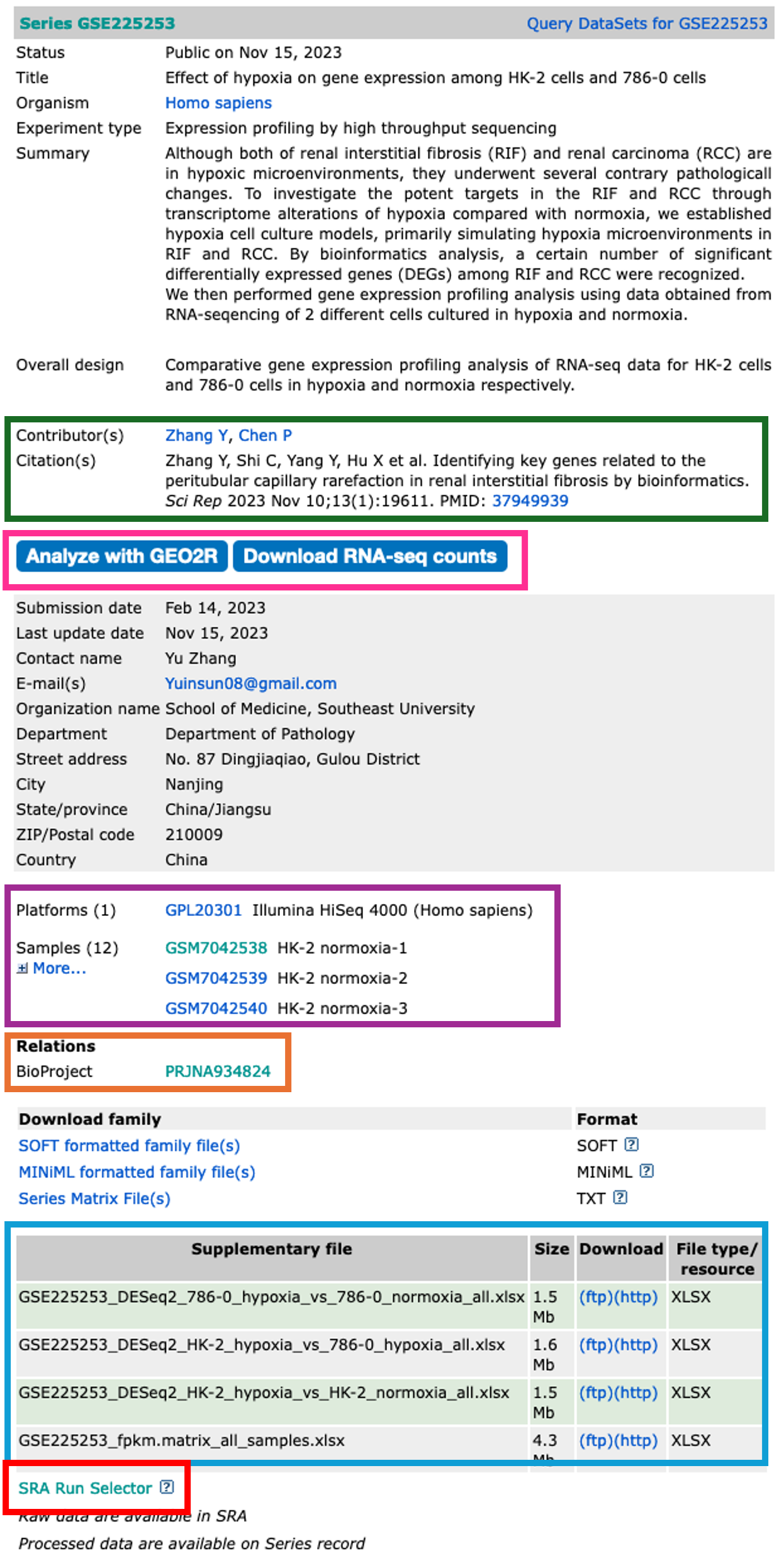
- The dataset series record page displays the all the relevant information about that dataset.
- Towards the top of the page, you will find information about the study in which the dataset was used.
Contributors and Citation
- The authors and any related publication can be found in the contributors and citations sections.
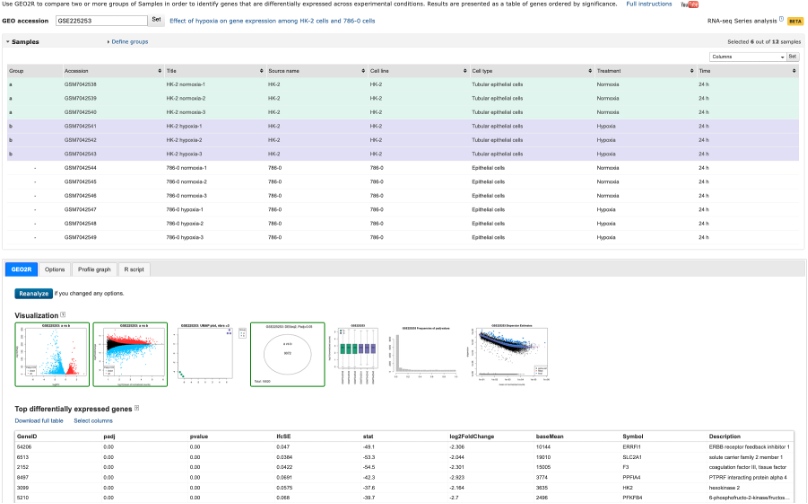
Analyze with GEO2R and Download RNA-seq counts
- The Analyze with GEO2R option has been on GEO for quite some time, and is a handy tool to use if you are performing the most basic of analyses.
- The tool allows you to define your own groups and can perform Differential Gene Expression (DGE) analyses rather quickly.
- It’s a great tool, but doesn’t always work on the dataset you want to analyse (depends on what data the authors have uploaded)
- It’s worth checking this tool out before continuing. We won’t be covering this tool during this course. If you would like a run through on it, please get in touch.
Analyze with GEO2R tool
- The Download RNA-seq counts option takes you to a page which provides you with download links to all of the uploaded and NCBI-generated data.
- This is really handy as it highlights what each piece of data is.
- Again, this may not contain the raw sequencing data, but worth checking before proceeding.
Download RNA-seq counts
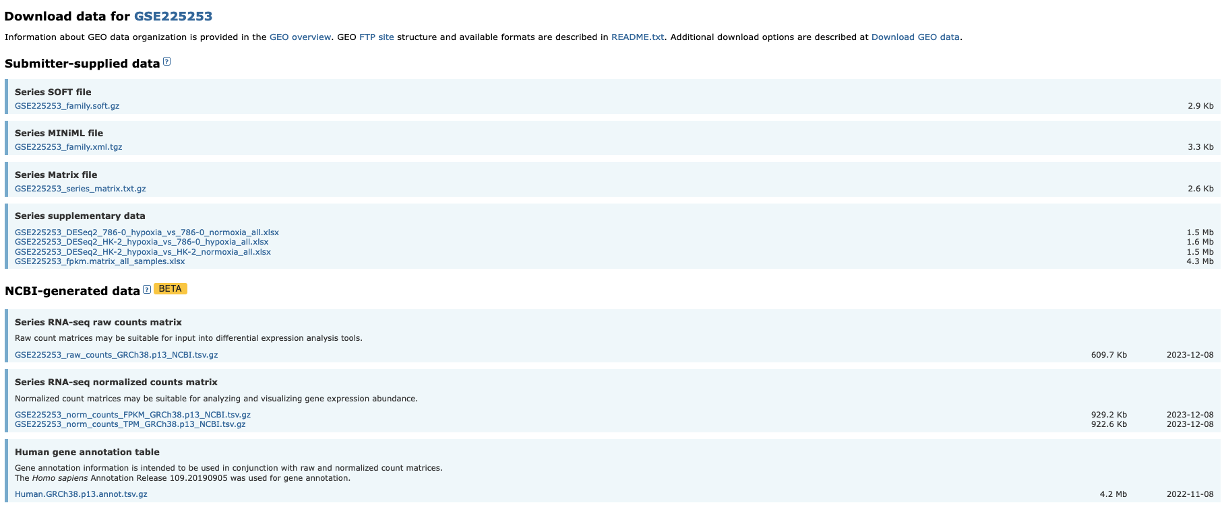
Platforms and Samples
- This section shows us information about the samples and what platform they were sequenced on.
BioProject
- The raw sequencing data for a dataset is stored in the Sequencing Read Archive (SRA). Once samples have been uploaded, they are given a BioProject ID.
- This BioProject ID link takes us straight to where the raw sequencing data is stored.
Supplementary files
- All the associated data is stored in this section.
- What you have here is completely down to how nice the authors are.
- For a GEO upload, the authors must upload normalised data tables in which their observations were made.
- Sometimes authors also upload Differentially Expressed Gene (DEG) tables and raw sequencing read counts.
- These authors have been so very kind to upload their DEGs, so there really is no need for us to continue on. But most authors do not upload these, so we will need to make them ourselves.
SRA Run Selector
- The SRA Run Selector link takes us directly to the SRA where we can download the sequencing data.
- Some may be asking, isn’t this the same as the BioProject ID link? Yes and no.
- The BioProject ID link takes you to an overview page, just like the GEO page we are currently on.
- The SRA Run Selector link takes us directly to the page where we can download the data.
Downloading the relevant data
- We will be downloading 6 normoxia samples, 3 from each cell line.
- To do this, we need to click on the SRA Run Selector link. 1) Once the new page has loaded, we can go ahead and use the filter tool on the top left to select 8: Treatment, then normoxia. 2) This filters the table at the bottom of the screen. We can then click the tick box at the top left of the table to select all 6 samples. 3) Once all samples are selected, we can now click on the sliding Selected tab so move it to the right. This filters the data to include only the samples we have selected. 4) Now we can click on the Accession list option. This downloads a text file called SRR_Acc_List.txt.
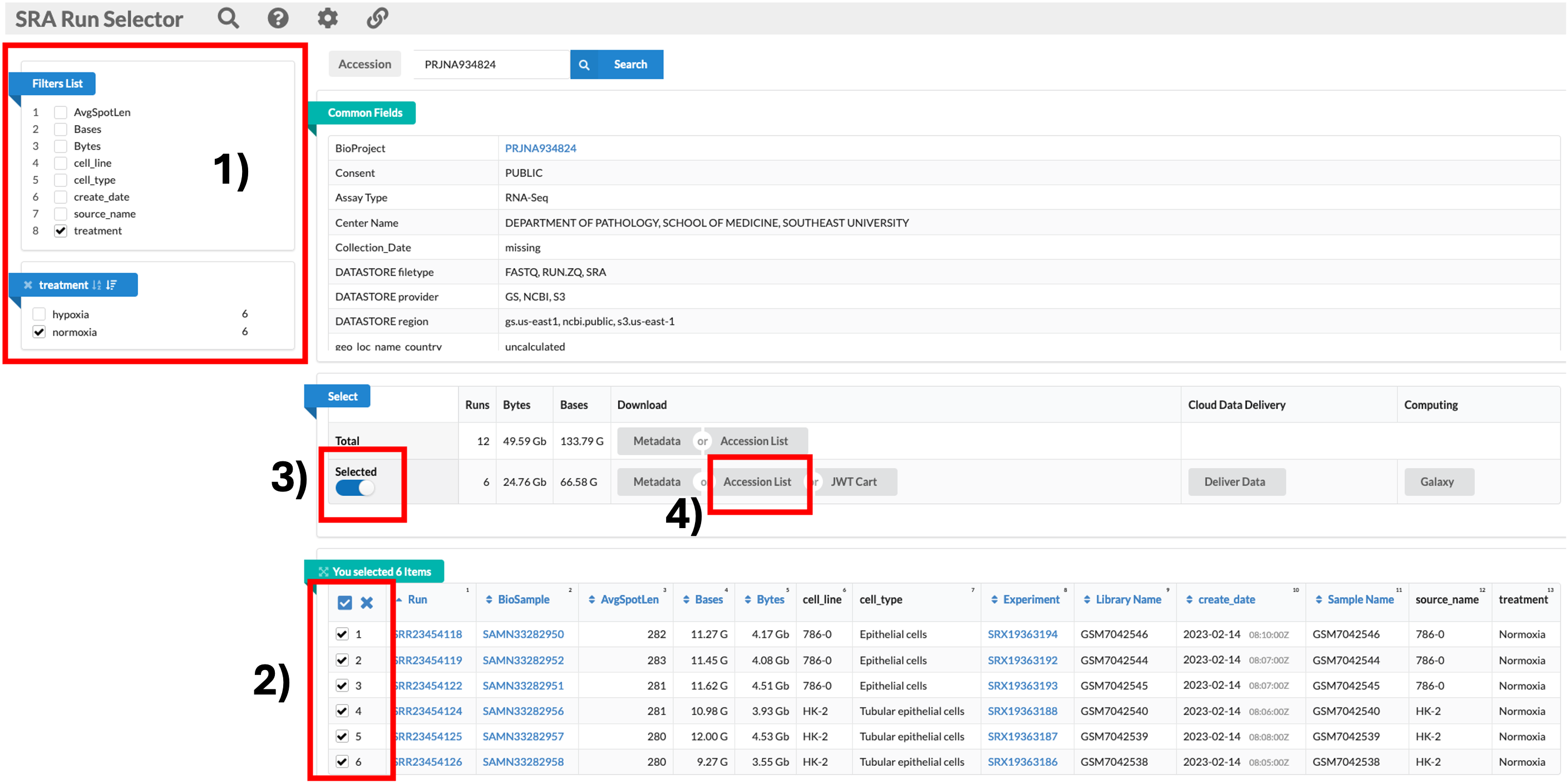
SRR_Acc_List.txt
SRR23454118
SRR23454119
SRR23454122
SRR23454124
SRR23454125
SRR23454126
nf-core/fetchngs pipeline
- Now that we have the sample IDs, we can go ahead and run the fetchngs pipeline.
Set-up
- Before we do anything, we first need to set-up our HAWK environment. Let’s login to HAWK.
- Once we are logged into HAWK, navigate to the scratch directory and make a working directory named rnaseq
cd /scratch/c.c1234567
mkdir rnaseq
- We need to change permissions of the rnaseq directory so that any daughter files and directories will inherit the same permissions:
chmod 777 rnaseq #777 gives read, write, and execute permissions for everyone
setfacl -d -m u::rwx,g::rwx,o::rwx rnaseq
- Now we can move into the rnaseq directory and make some daughter directories:
cd rnaseq
mkdir input output bin resources
ls
Required files
- Now that we have set-up the environment, we can go ahead and create the required files for the pipeline to run.
resources/ids.csv
- This file is a comma-separated value (.csv) file that contains the list of the sample IDs that we just downloaded.
What is a comma-separated values (.csv) file?
- A .csv file is simple text file that stores tabular data such as text and numbers in a specific structured format. - Each line of the file corresponds to one row in the table. - Within each line, fields(columns) are separated by commas. - For example, the .csv for the table below looks like:
| Column-1 | Column-2 | Column-3 |
|---|---|---|
| input1 | input2 | input3 |
| input4 | input5 | input6 |
| input7 | input8 | input9 |
Column-1,Column-2,Column-3
input1,input2,input3
input4,input5,input6
input7,input8,input9
- We have two choices to make this file: transfer the SRR_Acc_List.txt file over and rename it, or make the ids.csv file using nano and copy and paste the ids over.
- As we only have 6 sample IDs, I would reccommend the latter option. However, if we want to transfer the SRR_Acc_List.txt file over, we will need to use FileZilla or MobaXterm.
Transfer files using FileZilla
- After logging onto HAWK, navigate to the rnaseq directory on the connection window on the right hand side by pasting the filepath into the search bar and hitting enter:
/scratch/c.c1234567/rnaseq/resources
- Now find the SRR_Acc_List.txt file that you downloaded (probably Downloads directory) and simply drag and drop it from the left to right windows.
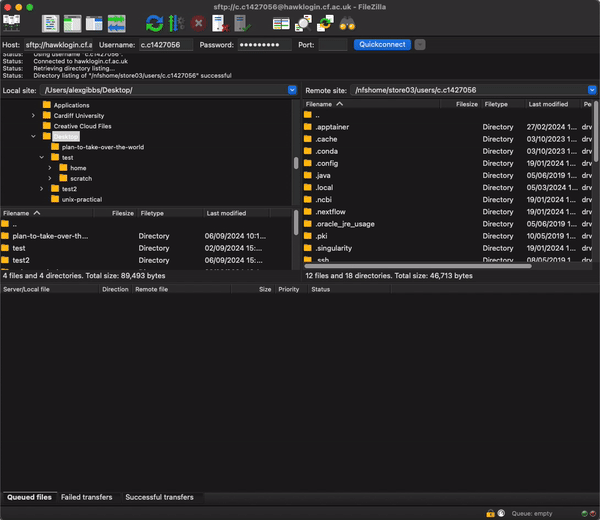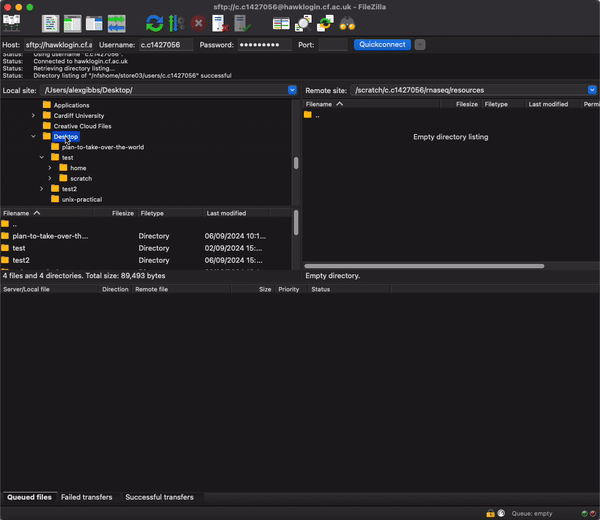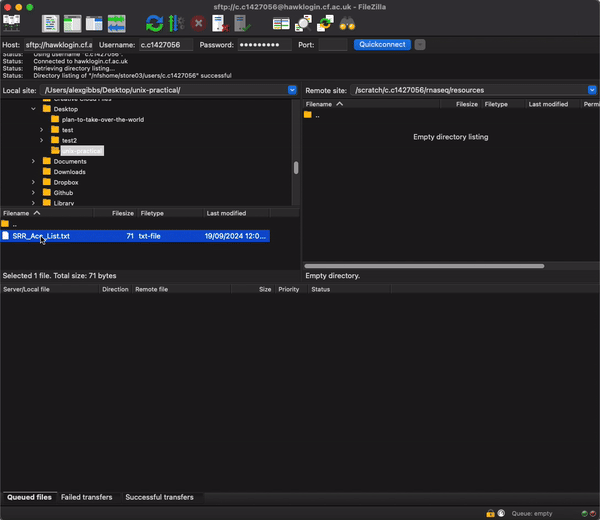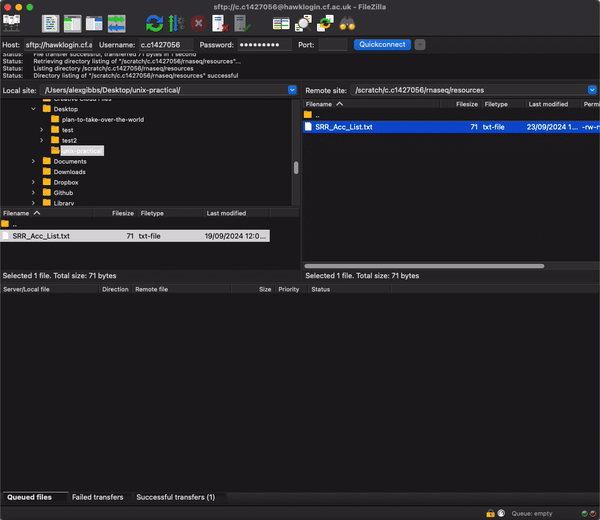 - Now we can change the name of the file. I would reccomend not using the mv command just incase there is a typo or you end up unwantingly removing the file.
- We will use the cp command instead. Here we copy the file to the same directory, but rename it to ids.csv.
- Now we can change the name of the file. I would reccomend not using the mv command just incase there is a typo or you end up unwantingly removing the file.
- We will use the cp command instead. Here we copy the file to the same directory, but rename it to ids.csv.
cp SRR_Acc_List.txt ./ids.csv
add mobaxterm section below
Transfer files using MobaXterm
- After logging onto HAWK, navigate to the rnaseq directory on the connection window on the right hand side by pasting the filepath into the search bar and hitting enter:
/scratch/c.c1234567/rnaseq/resources
- Now find the SRR_Acc_List.txt file that you downloaded (probably Downloads directory) and simply drag and drop it from the left to right windows.

Creating the file using nano
- To do this, we simply open the nano editor, copy and paste the sample IDs in, and save.
nano resources/ids.csv
SRR23454118
SRR23454119
SRR23454122
SRR23454124
SRR23454125
SRR23454126
ctrl + x
y
enter
</details>
ids.csv
SRR23454118
SRR23454119
SRR23454122
SRR23454124
SRR23454125
SRR23454126
resources/fetchngs-params.yaml
- This file contains all of the parameters needed for the pipeline to run.
- Instead of adding all of the options into the code when executing the pipeline, we can add them into this file. This keeps things tidier and easier to troubleshoot.
Creating fetchngs-params.yaml file
- To do this, we simply open the nano editor, copy and paste the following, and save.
nano resources/fetchngs-params.yaml
input: resources/ids.csv
outdir: input
nf_core_pipeline: rnaseq
email: your.email@cardiff.ac.uk
ctrl + x
y
enter
input - Where the input ids.csv file is located. outdir: Where to save the outputs to. nf_core_pipeline: Formats the output data so that it conforms with the required inputs for the rnaseq pipeline that we will be using further down the line.
fetchngs-params.yaml file
input: resources/ids.csv
outdir: input
nf_core_pipeline: rnaseq
email: your.email@cardiff.ac.uk
resources/my.config
- This file contains all of the configuration code required for the pipeline to run correctly on HAWK.
- We only need to change the email and scw account sections.
Creating my.config file
- To do this, we simply open the nano editor, copy and paste the following, and save.
nano resources/my.config
params {
config_profile_description = 'Super Computing Wales'
config_profile_contact = 'my.email@cardif.ac.uk'
config_profile_url = 'https://supercomputing.wales/'
}
singularity {
enabled = true
autoMounts = true
}
executor {
name = 'slurm'
queueSize = 10
queue = 'htc'
}
params {
max_memory = 180.GB
max_cpus = 20
max_time = 72.h
}
process {
beforeScript = 'module load singularity-ce/3.11.4'
clusterOptions = '--account=scw1234'
}
ctrl + x
y
enter
my.config file
params {
config_profile_description = 'Super Computing Wales'
config_profile_contact = 'my.email@cardif.ac.uk'
config_profile_url = 'https://supercomputing.wales/'
}
singularity {
enabled = true
autoMounts = true
}
executor {
name = 'slurm'
queueSize = 10
queue = 'htc'
}
params {
max_memory = 180.GB
max_cpus = 20
max_time = 72.h
}
process {
beforeScript = 'module load singularity-ce/3.11.4'
clusterOptions = '--account=scw1234'
}
bin/script.sh
- Here we will make a script file to keep track of what we have run etc.
- We will section off the file for each pipeline that we run.
Creating script.sh file
- To do this, we simply open the nano editor, copy and paste the code, and save.
nano bin/script.sh
#01
#load and make a new tmux session called fetchngs
#note the node you are working on [c.1234@cl1(hawk) bin]$
module load tmux
tmux new -s fetchngs/rnaseq/differentialabundance
#02
#load nextflow and singularity modules
module load nextflow/23.10.0
module load singularity/singularity-ce/3.11.4
#03
#execute fetchngs pipeline
nextflow run nf-core/fetchngs -r dev -profile singularity -c resources/my.config -params-file resources/fetchngs-params.yaml
#if pipeline fails for whatever reason, rerun using -resume command
nextflow run nf-core/fetchngs -r dev -profile singularity -c resources/my.config -params-file resources/fetchngs-params.yaml -resume
ctrl + x
y
enter
Executing the nf-core/prefetch pipeline
- Now we have everything ready to execute the pipeline.
- We should have the following directory and file structure:
.
└── rnaseq/
├── bin/
│ └── script.sh
├── resources/
│ ├── ids.csv
│ ├── fetchngs-params.yaml
│ └── my.config
├── input
└── output
- To run the pipeline, we need to be in the rnaseq directory.
- Then we can open a tmux session, load any required modules for the pipeline to run correctly, and close the session.
tmux
- tmux is a tool that we use to run multiple terminal sessions at once. - If we were to run the pipeline without tmux, we would have to stay logged into HAWK until the pipeline has finished running. - This can be problematic because 1) most pipelines can take a VERY long time to run, and 2) connection problems. If you are disconnected for any reason, the pipeline will cancel. - Using tmux allows us to open a new terminal window, run the pipeline, and close the session so that it runs in the background. - We can then log out of our HAWK session and log back in once we have been notified of the pipelines completion.Launch a tmux session
module load tmux
tmux new -s fetchngs
Load Modules
module load nextflow/23.10.0
module load singularity/singularity-ce/3.11.4
Execute pipeline
nextflow run nf-core/fetchngs -r dev -profile singularity -c resources/my.config -params-file resources/fetchngs-params.yaml
- Leave the pipeline run for a few minutes to ensure it is working, then we can close the session by doing the following:
Ctrl + b
then press d
- We will cover the outputs from this pipeline during the Day 2 session.
Day 2 - Processing RNAseq reads with nf-core/rnaseq pipeline
Recap from Day 1
- Yesterday we covered:
- How to use Unix.
- How to get onto HAWK and navigate it.
- How to execute the fetchngs pipeline.
Outputs from the differentialabundance pipeline
- We should all have had an email from SCW HAWK - HPC SERVICES notifying you of a successful pipeline run.
- Sometimes the email function doesn’t work. We can just log in and check ourselves.
- To check, we need to log back onto HAWK, load the tmux module, and then open the session that we created.
- NOTE: When using tmux, we need to make sure we are logged into the correct node. When we covered the log ins yesterday, we logged onto the cl1 node. The tmux session we made will only be present on the cl1 node. If we were to log in to the cl2 node, we wouldnt be able to find the tmux session.
#log onto HAWK
c.c1234567@hawklogin01.cf.ac.uk
PASSWORD
#move to the working directory (scratch)
cd /scratch/c.c134567/rnaseq
#load tmux
module load tmux
#open our tmux session
tmux attach -t fetchngs
- Upon opening the session, we should have a window that looks like this:
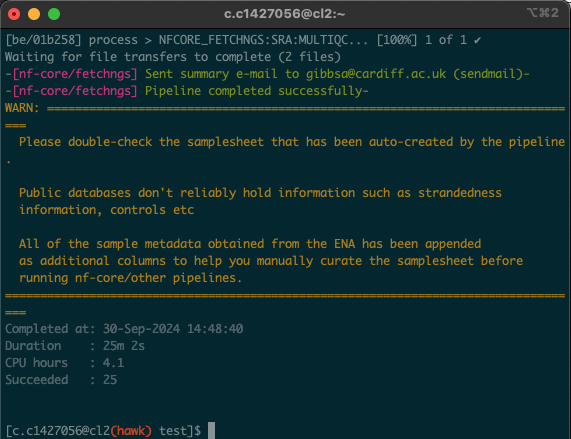
this is a test